
はじめに
こんにちは、こうへいです。クラウドソーシングを物色してたところ、GAS(Google App Scripte)に関する案件が多かったため、勉強を兼ねてWebサイトのスクレイピングをやってみました。
GAS(Google App Scripte)とは
概要
GAS(Google App Scripte)は、Googleが提供するアプリケーション開発プラットフォームです。JavaScriptを使ってGoogleスプレッドシートやGmailなどのGoogleサービスを連携しながら自動化することができます。また、APIを用いて外部のアプリと連携させることも可能です。代表的なGoogleアプリを以下に示します。
- Gmail
- Googleカレンダー
- Googleマップ
- Googleドライブ
- Googleドキュメント
- Googleスプレッドシート
- Googleスライド
- Googleフォーム

開発方法
GASの開発方式にはコンテナバインド型とスタンドアロン型の2通りがあります。コンテナバインド型は特定のGoogleサービスに紐づくプログラムを作成する際に利用する方式で、スタンドアロン型は特定のGoogleサービスに紐づかない独立したプログラムを作成する際に利用します。
コンテナバインド型
コンテナバインド型は特定のGoogleサービス上から起動します。ここでは、Googleスプレッドシート上でボタンを押してプログラムを実行する場合の開発の流れについて説明します。
まずはhttps://docs.google.com/spreadsheetsから新規シートを作成し、拡張機能タブからApp ScripteをクリックしてGASのエディタ画面を開きます。次にエディタ画面でプログラムを記述します。そしてスプレッドシートに戻り、挿入タブから図形描画をクリックします。ボタンを追加したら右上の…からスクリプト割り当てをクリックし、作成したプログラムの関数名を設定します。最後に作成したボタンをクリックすると、指定した関数が呼び出されます。
スタンドアロン型
Googleドライブからプロジェクトを作るみたいです。
注意点
GASを使うにあたって注意点が2つあります。
・ローカルファイルの操作は行えない。
GASはGoogleドライブ上のファイルにしかアクセスできないため、使用したいファイルはすべてアップロードしなければなりません。
・実行時間の制限がある。
スクリプトの実行時間:最大6分 / 1回
カスタム関数の実行時間:最大30秒 / 1回
スクレイピングの準備
注意点
Webサイトのスクレイピングは法律に触れる可能性があるため注意が必要です。スクレイピングは人間がWebサイトを検索して閲覧するのと同等な行為のため、基本的にスクレイピングによる情報の収集自体に違法性はありませんが、収集したデータの扱い方によっては違法となる可能性があります。また、サイトによってはスクレイピング自体を禁止している場合もあります。ただし、スクレイピングが禁止されているWebサイトもAPI経由であれば情報収集できることが多いです。以下、スクレイピングが禁止されているWebサイトの一例です。
- Amazon
- 楽天
- Youtube


Webサイトの種類
Webサイトのスクレイピングを行う際、そのサイトが静的か動的か見極める必要があります。静的サイトとは、誰がいつどこで見ても同じ情報が表示されるサイト(ブログなど)のことで、動的サイトは、ユーザ、時間、場所などの特定の条件に応じて異なる情報を自動で表示するサイト(天気予報など)のことです。スクレイピングは基本的にHTMLの情報を抽出する行為を指しますが、動的サイトではJavaScriptが使われていることが多く、HTMLだけでは情報を完全に抽出できないことがあるため、注意が必要です。
Parserライブラリの導入
スクレイピングに特化したParserライブラリを導入します。GASのエディタ画面からライブラリをクリックし、以下のスクリプトIDで検索して追加します。
スクリプトID:1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNw

PhantomJsCloudのAPIキー取得
動的サイトをスクレイピングしたい場合は、JavaScriptなどの動的な情報を一度HTMLに反映させてからスクレイピングを始める必要があります。そこで、PhantomJsCloudというヘッドレスブラウザのクラウドサービスを利用するのですが、GASからこのサービスを利用するためにAPIキーを取得します。以下を参考にしました。
PhantomJsCloudは無料プランだと1日500回のAPIリクエストまで可能です。

静的サイトのスクレイピング
静的サイトのスクレイピングでは、このブログのトップページを対象にします。以下の情報をスクレイピングし、Googleスプレッドシートに表として出力することを考えます。
- 各記事の名前
- 各記事のURL
- 各記事の分類
- 各記事の投稿日時
スクレイピング方針の決定
コーディングの前にスクレイピングする対象がHTML内でどのように記述されているか確認し、抽出の方針を決定する必要があります。HTMLのコードはF12キーで確認します。以下は該当する部分のみを抜き出したHTMLコードです。aタグが各記事に対応していることが分かります。
<!DOCTYPE html>
<html lang="ja">
<head> ... </head>
<body>
<a href="https://gadgetton.net/2022/10/01/..." class="entry-card-wrap a-wrap border-element cf" title="隠しコマンド">
<span class="cat-label cat-label-3">Web系</span>
<h2 class="entry-card-title card-title e-card-title" itemprop="headline">隠しコマンド</h2>
<span class="entry-date">2022.10.01</span>
</a>
<a href="https://gadgetton.net/2022/05/24/..." class="entry-card-wrap a-wrap border-element cf" title="Highlighting Code BlockプラグインにArduino言語を追加">
<span class="cat-label cat-label-3">Web系</span>
<h2 class="entry-card-title card-title e-card-title" itemprop="headline">Highlighting Code BlockプラグインにArduino言語を追加</h2>
<span class="entry-date">2022.05.24</span>
</a>
<a href="https://gadgetton.net/2022/05/22/..." class="entry-card-wrap a-wrap border-element cf" title="数式エディタとコード・テーブル表示の設定">
<span class="cat-label cat-label-3">Web系</span>
<h2 class="entry-card-title card-title e-card-title" itemprop="headline">数式エディタとコード・テーブル表示の設定</h2>
<span class="entry-date">2022.05.22</span>
</a>
<a href="https://gadgetton.net/2022/05/16/..." class="entry-card-wrap a-wrap border-element cf" title="目次自動ハイライト">
<span class="cat-label cat-label-3">Web系</span>
<h2 class="entry-card-title card-title e-card-title" itemprop="headline">目次自動ハイライト</h2>
<span class="entry-date">2022.05.16</span>
</a>
<a href="https://gadgetton.net/2022/05/15/..." class="entry-card-wrap a-wrap border-element cf" title="ブログ開設">
<span class="cat-label cat-label-3">Web系</span>
<h2 class="entry-card-title card-title e-card-title" itemprop="headline">ブログ開設</h2>
<span class="entry-date">2022.05.15</span>
</a>
</body>
</html>まずclass=”entry-card-wrap a-wrap border-element cf”のaタグを抽出することで、各ブロック要素ごとデータを抽出します。さらに、それぞれのブロックの中で以下のデータ抽出を行います。このように階層ごとに抽出することで、抽出データ間のずれをなくします。
- 各記事の名前 → class=”entry-card-title card-title e-card-title”のh2タグ
- 各記事のURL → aタグのhref属性
- 各記事の分類 → class=”cat-label cat-label-3″のspanタグ
- 各記事の投稿日時 → class=”entry-date”のspanタグ
実装
https://gadgetton.net/から記事一覧データをスクレイピングし、結果をGoogleスプレッドシートに出力するコードです。今回はコンテナバインド型で実装しています。
//静的サイトスクレイピング
function start_static_scraping(){
// HTMLの取得
const url = "https://gadgetton.net/";
var html = UrlFetchApp.fetch(url).getContentText();
// 候補ブロックの取得
var blocks = Parser.data(html).from('<a').to('</a>').iterate();
// データ抽出
var article = []; // 記事データ格納用
var id = 0; // 対象カウント
for(var b = 0; b < blocks.length; b++){
// 候補ブロックから対象外のものを除く
var isTarget = blocks[b].includes('class="entry-card-wrap a-wrap border-element cf"');
if(isTarget){
// 対象のデータ抽出
var artname = Parser.data(blocks[b]).from('<h2 class="entry-card-title card-title e-card-title" itemprop="headline">').to('</h2>').build();
var arturl = Parser.data(blocks[b]).from('href="').to('"').build();
var arttype = Parser.data(blocks[b]).from('<span class="cat-label cat-label-3">').to('</span>').build();
var artdate = Parser.data(blocks[b]).from('<span class="entry-date">').to('</span>').build();
article[id] = {id:id+1, name:artname, url:arturl, type:arttype, date:artdate};
id++;
}
}
console.log(article);
// スクレイピング結果の作成
const left = 2;
const top = 2;
const sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName('静的サイト');
sheet.getRange(top, left+0).setValue("ID");
sheet.getRange(top, left+1).setValue("記事名");
sheet.getRange(top, left+2).setValue("URL");
sheet.getRange(top, left+3).setValue("分類");
sheet.getRange(top, left+4).setValue("投稿日");
for(var i = 0; i < article.length; i++){
sheet.getRange(top+i+1, left+0).setValue(article[i].id)
sheet.getRange(top+i+1, left+1).setValue(article[i].name)
sheet.getRange(top+i+1, left+2).setValue(article[i].url)
sheet.getRange(top+i+1, left+3).setValue(article[i].type)
sheet.getRange(top+i+1, left+4).setValue(article[i].date)
}
// 罫線
sheet.getRange(top, left, article.length+1, 4+1).setBorder(true, true, true, true, true, true, "black", SpreadsheetApp.BorderStyle.SOLID);
sheet.getRange(top, left, article.length+1, 4+1).setBorder(true, true, true, true, null, null, "black", SpreadsheetApp.BorderStyle.SOLID_THICK);
sheet.getRange(top, left, 1, 4+1).setBorder(true, true, true, true, null, null, "black", SpreadsheetApp.BorderStyle.SOLID_THICK);
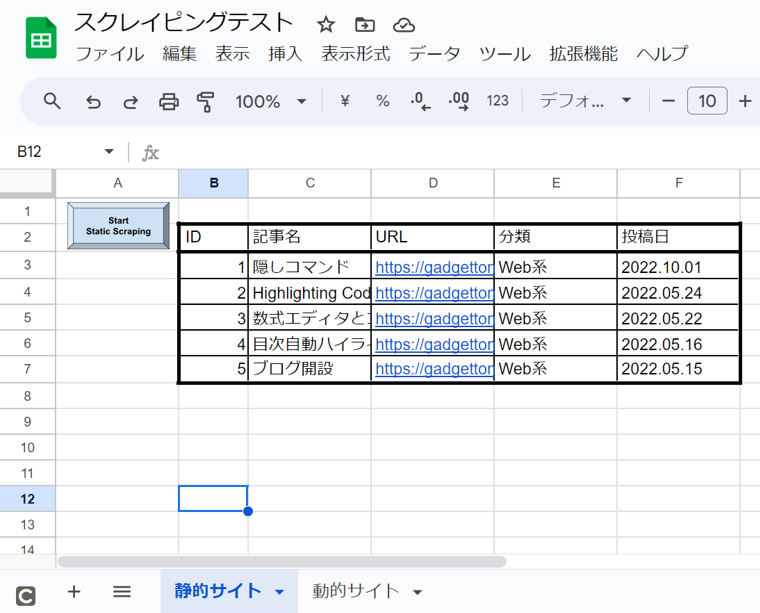
}以下、出力された表です。
動的サイトのスクレイピング
動的サイトのスクレイピングでは、めざましテレビの占いサイトを対象にします。以下の情報をスクレイピングし、Googleスプレッドシートに表として出力することを考えます。
- 日付
- ランキング
- 星座
- 占い結果
- ラッキーアイテム

スクレイピング方針の決定
以下は該当する部分のみを抜き出したHTMLコードです。liタグが各星座に対応していることが分かります。
<!DOCTYPE html>
<html lang="ja">
<head> ... </head>
<body>
<li class="result1">
<p class="rank">1<span>位</span></p>
<p class="name id01">おひつじ座</p>
<p class="text">チャレンジがうまくいく情報を入手。<br>難易度が高いことに挑戦してみよう。</p>
<p class="point">
アドバイス:午前中に集中的に行動をする<br>
ラッキーパーソン:上品な人<br> <!---->
ラッキーポイント:ロボットのチャーム
</p>
</li>
<li class="result2">
<p class="rank">2<span>位</span></p>
<p class="name id05">しし座</p>
<p class="text">初めての経験で大収穫が。<br>興味があることにトライ。</p>
<p class="point">
ラッキーポイント:シルバーのネックレス
</p>
...
</li>
</body>
</html>class=”result**”のliタグを抽出した後、それぞれのブロックの中で以下のデータ抽出を行います。
- ランキング → class=”rank”のpタグ
- 星座 → class=”name id**”のpタグ
- 占い結果 → class=”text”のpタグ
- ラッキーアイテム → class=”point”のpタグ
※めざましテレビの占いサイトではjson形式のファイルも用意されているみたいですが、今回は勉強のためHTMLからスクレイピングします。
実装
めざましテレビの占いサイトから占いデータをスクレイピングし、結果をGoogleスプレッドシートに出力するコードです。今回はコンテナバインド型で実装しています。
//動的サイトスクレイピング
function start_dynamic_scraping(){
// HTMLの取得
const url = "https://www.fujitv.co.jp/meza/uranai/index.html";
// var html = UrlFetchApp.fetch(url).getContentText();
var html = phantomJSCloudScraping(url);
// 候補ブロックの取得
var blocks = Parser.data(html).from('<li class="result').to('</li>').iterate();
// データ抽出
var uranai = []; // 占いデータ格納用
for(var b = 0; b < blocks.length; b++){
// 対象のデータ抽出&整形
var rank = Parser.data(blocks[b]).from('<p class="rank">').to('<span>').build();
var name = Parser.data(blocks[b]).from('<p class="name ').to('/p>').build();
name = Parser.data(name).from('>').to('<').build();
var text = Parser.data(blocks[b]).from('<p class="text">').to('</p>').build();
text = text.replace(/<br>/g, '\n');
var point = Parser.data(blocks[b]).from('<p class="point">').to('</p>').build();
point = point.replace(/ /g, '').replace(/<!---->/g, '').replace(/<br>/g, '').trim();
uranai[b] = {rank:rank, name:name, text:text, point:point};
}
console.log(uranai);
// スクレイピング結果の作成
const left = 2;
const top = 2;
const sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName('動的サイト');
sheet.getRange(top, left+0).setValue("ランキング");
sheet.getRange(top, left+1).setValue("星座");
sheet.getRange(top, left+2).setValue("占い結果");
sheet.getRange(top, left+3).setValue("ラッキーポイント");
for(var i = 0; i < uranai.length; i++){
sheet.getRange(top+i+1, left+0).setValue(uranai[i].rank)
sheet.getRange(top+i+1, left+1).setValue(uranai[i].name)
sheet.getRange(top+i+1, left+2).setValue(uranai[i].text)
sheet.getRange(top+i+1, left+3).setValue(uranai[i].point)
}
// 罫線
sheet.getRange(top, left, uranai.length+1, 3+1).setBorder(true, true, true, true, true, true, "black", SpreadsheetApp.BorderStyle.SOLID);
sheet.getRange(top, left, uranai.length+1, 3+1).setBorder(true, true, true, true, null, null, "black", SpreadsheetApp.BorderStyle.SOLID_THICK);
sheet.getRange(top, left, 1, 3+1).setBorder(true, true, true, true, null, null, "black", SpreadsheetApp.BorderStyle.SOLID_THICK);
}
// 動的サイトのHTML取得
function phantomJSCloudScraping(URL){
let key = "API Key";
let option = {url:URL, renderType:"HTML", outputAsJson:true};
let payload = JSON.stringify(option);
payload = encodeURIComponent(payload);
let apiUrl = "https://phantomjscloud.com/api/browser/v2/"+ key +"/?request=" + payload;
let response = UrlFetchApp.fetch(apiUrl);
let json = JSON.parse(response.getContentText());
let source = json["content"]["data"];
return source;
}50行目にPhantomJsCloudのAPIキーを入力する部分があるため、以下のサイトで確認する必要があります。

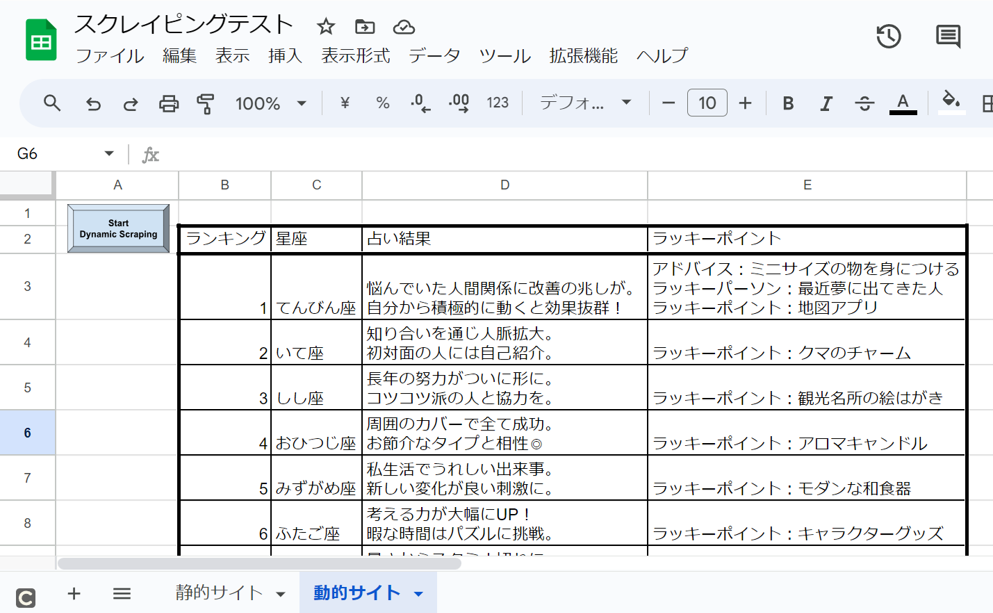
以下、出力された表です。

コメント